เอา feature จาก Caffe มาเล่น
Caffe คืออะไร
Caffe เป็นชุดคำสั่งสำหรับใช้งาน deep neural network ตระกูล convolutional neural network หรือ CNN ที่ใช้งานง่าย สามารถใช้ประโยชน์จาก GPU บนเครื่องได้ มี manual ในการนำเข้าข้อมูล และทดสอบ รวมถึง tutorial ค่อนข้างเยอะอยู่ โดยสามารถ download ได้จาก http://caffe.berkeleyvision.org/
บน OSX เราสามารถสั่ง port install caffe ได้ แต่เท่าที่ลองพวก tools อย่าง feature_extraction มันไม่มาด้วย ดังนั้นถ้าจะให้ง่ายก็คือเอา source มา compile เองจะดีกว่า โชคดีที่แลป ณัฐชัย ลงให้แล้ว เลยไม่ต้องทำเอง เห็นว่าวุ่นอยู่เหมือนกัน
ในการใช้งาน CNN สำหรับ classification แล้วโครงสร้างที่ใช้นั้นมักจะประกอบด้วย 2 ส่วนคือ ส่วน feature extractor (ที่ประกอบด้วยชั้น convolution สลับกับชั้น max-pooling) และ ส่วน classifier (ที่มักจะเป็น fully connected MLP) อยู่ข้างบนส่วน feature extractor จุดเด่นของ CNN ก็คือโครงสร้างทั้งสองส่วนนี้ถูก train มาพร้อมๆ กันดังนั้น feature extractor ที่ได้จึงสามารถสกัด feature ที่เฉพาะกับงานที่พิจารณาได้ ซึ่งทำให้ได้ผลที่ดีกว่าการใช้ generic feature อย่าง สีของ pixel, gradient หรือรหัส LBP เป็นต้น ทำให้เกิดแนวความคิดที่จะ train CNN เพื่อนำมาใช้เป็น feature extractor เฉพาะงานแทน ซึ่ง Caffe ก็ดูเหมือนจะ support idea นี้อยู่ แต่ในทางปฏิบัตินั้นมันไม่ง่ายอย่างที่คิด เลยจดบันทึกวิธีทำซักหน่อย อาจจะมีประโยชน์สำหรับคนที่เริ่มเล่น Caffe เหมือนผม (บางทีอาจจะมีวิธีที่ง่ายกว่าแต่หาไม่เจอ)

feature_extractor
ผมสนใจที่จะเอา network ชื่อ AlexNet มาลองเล่นดู ซึ่งใน Caffe เองก็มี model นี้ที่ถูก train แล้วมาด้วย ตามรูปข้างบน ส่วน feature extractor จะประกอบด้วย ชั้น convolution, normalize และ pooling สลับกัน ตามด้วยส่วน classifier ที่มี 3 ชั้นหลักคือ fc6, fc7 และ fc8
ของที่ผมต้องการคือใส่ภาพเข้าไปแล้วเก็บ output จากชั้น fc7 (ชั้นก่อนสุดท้าย) มาเล่นดู เพื่อการนี้ในชุดคำสั่งของ Caffe นั้นมี tool ที่เราต้องใช้คือ feature_extractor โดยที่ feature_extractor นี้รับ argument นำเข้าดังนี้
feature_extractor alexnet.caffemodel my.prototxt fc7 outputdir m lmdb GPU
โดยที่
- alexnet.caffemodel เป็นไฟล์ของ AlexNet ที่ถูก train แล้วโดย Caffe สามารถ download ได้จาก http://dl.caffe.berkeleyvision.org/bvlc_alexnet.caffemodel หรือถ้า train เองอย่างที่แลปก็เอาไฟล์ที่ได้มาใช้ก็ได้
- my.prototxt เป็นไฟล์ prototxt ที่เอามาจาก train_val.prototxt แต่เราแก้บางส่วนเพื่อให้สามารถ process ข้อมูลของเราได้ โดยส่วนหลักๆ ที่แก้มี 3–4 ส่วนใน layer แรกที่ชื่อ “data” นั่นคือ
2.1 แก้ type จาก “Data” เป็น “ImageData”
2.2 แก้ source รายชื่อของไฟล์รูปภาพที่เราต้องการประมวลผล โดย format ของไฟล์รูปภาพนี้คือใน 1 บรรทัดจะมี path ไปยังไฟล์ที่ต้องการ ตามด้วย class label ของมัน
2.3 ขนาดของ mini_batch โดย feature_extractor นั้นจะทำการประมวลผลภาพจำนวน mini_batch * m (m มาจาก argument ในตอน run) เสมอ โดยค่า default ของมันคือ 50 ดังนั้นถ้าเราทำตามตัวอย่าง feature_extractor จะสกัดลักษณะเด่นจากภาพเพียง 500 ภาพเท่านั้น ถ้าเราต้องการ process ทุกภาพ ให้ตั้งค่า mini_batch และ m ให้ผลคูณเท่ากับจำนวนภาพในรายชื่อในไฟล์
2.4 ควรทราบว่าภาพของ MNIST นั้นมีขนาดจริงคือ 28x28 pixels แต่เพื่อให้ใช้กับ AlexNet ได้ เราจึงขยายภาพขึ้นเป็น 256x256 pixels โดยการตั้งค่า ‘new_width’ กับ ‘new_height’ เป็น 256 ทั้งคู่ - fc7 เป็นชื่อของชั้นที่เราต้องการเอาค่ามาใช้ เราสามารถระบุชื่อหลายชั้นได้โดยขั้นด้วย ‘,’ เช่น fc7,fc8 เป็นต้น (ยังไม่ได้ลองเอง)
- outputdir เป็นชื่อ directory ที่ Caffe จะ save feature ที่สกัดออกมาให้เรา
- m เป็นจำนวน mini_batch
- lmdb คือ format ของฐานข้อมูลที่ Caffe จะ save feature ที่สกัดออกมาให้เรา
- GPU ระบุว่าต้องการประมวลผลด้วย GPU เข้าใจว่าถ้าไม่ใส่ default จะใช้ CPU
lmdb
lmdb เป็นหนึ่งใน format ของไฟล์ชุดข้อมูลที่ Caffe ใช้ ในย่อหน้าก่อนเราสั่งให้ Caffe ประมวลผลจากภาพโดยตีง แต่ Caffe ก็สามารถ load ข้อมูลจากไฟล์ format อื่นได้เช่นกัน อย่าง lmdb หรือ leveldb เป้นต้น
ถ้าเรามี tool อื่นที่รับข้อมูลใน format lmdb หรือถ้าเราจะนำข้อมูลที่ได้มาประมวลผลซ้ำด้วย Caffe เราก็สามารถทำงานกับไฟล์ที่ได้จาก feature_extractor โดยตรง โชคร้ายที่ผมอยากลองใช้ Caffe feature กับ tool อื่น อย่าง LIBSVM หรือใช้กับชุดคำสั่งของตัวเองซึ่งทำให้ต้องมานั่งแกะ lmdb format เพิ่ม
จากการไป google ดูหลายๆ ที่ ก็ได้ code ข้างล่างนี้มาสำหรับอ่านข้อมูล format lmdb โดยที่ ‘mdb_dirname’ คือ directory ที่ได้จาก Caffe นั่นเอง โดยปกติแล้วใน directory นี้จะมีไฟล์ 2 ไฟล์คือ ‘data.mdb’ และ ‘lock.mdb’

ข้อมูลหนึ่งๆ ที่ได้มาจาก lmdb นั้นจะอยู่ในรูปคู่ (key, data) โดยที่ทั้ง key และ data ต่างก็เป็น string เมื่อค้นต่อไปใน code ของ Caffe จึงรู้ว่า string ของ data นั้นได้จากการทำ serialize ข้อมูลจาก class ที่ชื่อ ‘Datum’ ที่สร้างจาก protocol buffers หรือ protobuf ของ google นั่นเอง ดังนั้นเราจึงต้องไปค้นต่อ
Protobuf
เท่าที่เข้าใจ protobuf (https://developers.google.com/protocol-buffers/) เป็น framework สำหรับ serialize ข้อมูลต่างๆ อารมณ์เดียวกับ XML หรือ JSON ยังไม่ได้ไปดูว่าทำมาทำไม
การใช้งานคือเราต้องกำหนดนิยามของข้อมูลของเราก่อน ลงในไฟล์ .proto จากนั้นให้ compile มันด้วย protoc โดยระบุภาษาที่ต้องการให้ protoc output code ออกมาให้ เช่น
protoc datum.proto — cpp_out=./
ในกรณีนี้ protoc ก็จะ process ไฟล์ datum.proto และสร้าง code ชื่อ datum.pb.h กับ datum.pb.cc มาให้ ซึ่งเราสามารถเอาไปใส่ใน code C++ ของเราเพื่อใช้งาน structure ต่างๆ ใน datum.proto ได้
เข้าใจเองว่าถ้าเรากำหนด output เป็นภาษาอื่น เราก็จะได้ชุดคำสั่งในภาษานั้นออกมาเอาไว้ใช้ใน code ของเรา โดยที่ข้อมูลนี้สามารถส่งข้ามภาษาได้ เพราะผ่านการ serialize แบบเดียวกัน
ในกรณีของเรานั้นเราก๊อปเอาเฉพาะส่วน Datum จาก caffe.proto มาใช้ ตาม code ข้างล่างนี้ (จริงๆ เอา caffe.pb.h กับ caffe.pb.cc มาใช้ก็คงได้ แต่ช่วงที่กำลังงมมี compiler/link error ขึ้นมาเยอะเลยตัดมาเฉพาะส่วนที่คิดว่าเกี่ยวกับงาน)
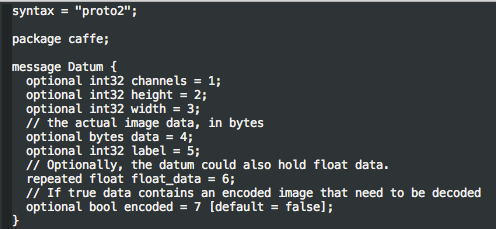
โดยเราเรียกใช้ Datum นี้ได้โดย

และเราต้องใส่ ‘GOOGLE_PROTOBUF_VERIFY_VERSION;’ ไว้ใน main ด้วย
ปัญหาเล็กน้อยที่เจอคือ label ของข้อมูลนั้นหายไป ไม่รู้ทำไม
การ build
หนึ่งในปัญหาใหญ่สุดของงานนี้คือการ compile+link code ให้เป็น exe ผมทำบน OSX ที่ลง Caffe ผ่าน port ซึ่งทำให้ได้ lmdb กับ protobuf มาพร้อมกัน (อันนี้ไม่แน่ใจ ตอนแรกคิดว่าไม่มีเลยสั่งลงผ่าน brew ไปอีกรอบ)
ตอนสั่ง build ก็เจอปัญหาหลายอย่าง ส่วนมากเกี่ยวกับการ link สังเกตจาก error msg พวก undefined reference … วิธีแก้ก็คือพยายามเดาเอาว่าขาดอะไรก็ link ไปให้ครบ ซึ่งทำได้เกือบหมด มาติดที่ protobuf จากการมั่วไปมั่วมาพบว่าวิธีแก้ทำได้โดยสั่งให้ link ไปกับ static library (.a ใน Linux และ OSX) เลย นั่นคือแทนที่เราจะ link ผ่าน -lprotobuf ให้เราเพิ่ม ‘libprotobuf.a’ เข้าไปใน exe แทน โดยสั่งตามข้างล่างแทน
g++ -o readlmdb readlmdb.cpp datum.pb.cc /opt/local/lib/libprotobuf.a -I/opt/local/include/ -lstdc++ -L/opt/local/lib/ -llmdb
พอลองเอาคำสั่งนี้ไปใส่ Makefile ให้แยก compile กับมีปัญหาอีก เลย hard code คำสั่งนี้ไปเลย
AlexNet feature กับ MNIST
เมื่อพอจะเข้าใจกระบวนการทั้งหมดแล้วเราก็มาลองของที่คุ้นเคยกันหน่อย นั่นคือชุดข้อมูล MNIST จริงๆ แล้วใน tutorial ของ Caffe มีวิธีสร้างโครงสร้าง LeNet และ train สำหรับข้อมูล MNIST อยู่ แต่นั่นคือการทดลองโดยใช้ Caffe ทั้งหมด ผมอยากรู้ว่าถ้าเราเอาข้อมูลจาก Caffe ไปใช้ที่อื่นจะเป็นไง ดังนั้นผมเลยเขียนชุดคำสั่งเพิ่มอีกคือ
- คำสั่งสำหรับอ่าน MNIST และ save ภาพแบบแยกไฟล์ละตัวอย่าง (ผมใช้ .png)
- คำสั่งสำหรับดึง label จากข้อมูล MNIST
- คำสั่งสำหรับแปลง lmdb (จาก AlexNet)+ label ให้อยู่ใน LIBSVM format
จากนั้นก็เอาไฟล์ LIBSVM format ที่ได้ไปลอง train + test ด้วย LIBSVM โดยใช้ linear kernel ธรรมดา (เพราะอุตสาห์ใช้ feature extractor ที่น่าจะเทพแล้วทั้งที) ดังนั้น SVM ก็คือ linear classifier ที่ถูก train ด้วย maximum margin criteria
error ที่ได้ เมื่อเทียบกับผลอื่นจาก http://yann.lecun.com/exdb/mnist/index.html คือ
- AlexNet feature + SVM (linear kernel): 1.0%
- Linear Classifier: 12.0%
- SVM (Gaussian kernel): 1.4%
- SVM (Poly deg 4): 1.1%
ก็ถือได้ว่าไม่แย่นัก กระบวนการที่ทำทั้งหมดก็น่าจะถูกแล้ว
